Hoy en día es muy común emplear el término Big Data en nuestro entorno en empresas privadas y en organismos públicos. Tanto es así que cada vez más empresas basan sus decisiones estratégicas en el análisis de grandes volúmenes de datos, utilizando herramientas Big Data.
¿Pero qué se conoce como Big Data?
Qué es el Big Data
Según Gartner, Big Data es “un gran volumen, velocidad o variedad de información que demanda formas costeables e innovadoras de procesamiento de información que permitan ideas extendidas, toma de decisiones y automatización del proceso”.
Esta definición resume las características más importantes del Big Data conocidas originalmente como las tres Vs: Volumen, Velocidad y Variedad. Dos nuevas Vs se han sumado a este concepto: Veracidad y Valor, para resaltar la importancia de calidad y no sólo de cantidad.
Actualmente las empresas más valoradas en el mundo son aquellas no sólo capaces de procesar grandes volúmenes de datos sino de extraer valor de ellos guiando la toma de decisiones estratégicas en lo que le “dicen” los datos.
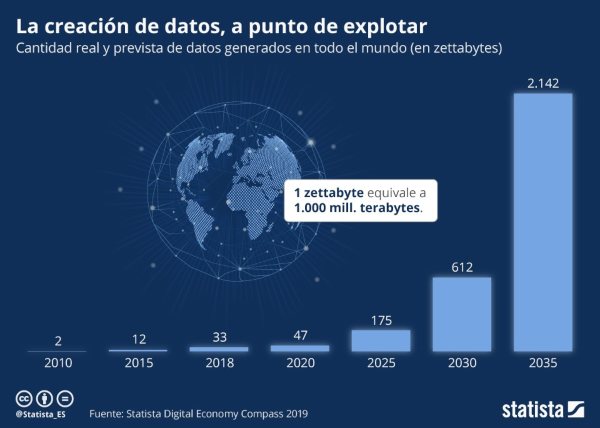
Cada vez se generan más datos
¿Qué factores han propiciado el crecimiento exponencial en la cantidad de datos generados diariamente?
La irrupción de nuevas tecnologías como los smartphones, las redes sociales o el IoT (Internet of Things) con los incrementos exponenciales en conectividad a internet y en la capacidad de procesamiento, tanto en la nube, cloud computing como en dispositivos locales edge computing.
Otro factor clave ha sido el desarrollo de herramientas Big Data que permiten extraer, transformar, almacenar, procesar y visualizar dichos datos.
Tradicionalmente los datos se han almacenado en bases de datos relacionales alojadas en un servidor. Este tipo de bases de datos, generalmente SQL, se basan en tablas y resultan muy eficientes con cantidades de datos moderadas por su rapidez de consulta y de inserción de datos y por su consistencia.
Por otra parte, a medida que aumenta el volumen de datos almacenado, la eficiencia de esta tecnología va bajando, dado que a mayor cantidad de datos, mayor tiempo de respuesta o latencia. Además, la cantidad de datos que se puede almacenar está limitada por el tamaño del disco duro del servidor donde se ha alojado la base de datos.
Aunque es posible escalar el sistema añadiendo un disco duro de mayor capacidad, no resulta una tarea trivial y sencilla, por lo que en la fase de diseño de la base de datos hay que tener en cuenta la cantidad de datos máxima que va a tener que almacenar el sistema.
Cinco herramientas Big Data
Vamos a analizar cinco herramientas Big Data imprescindibles.
Apache Hadoop
No se puede hablar de herramientas Big Data sin mencionar Apache Hadoop. Se trata de un framework open source que permite, entre otras cosas, almacenar y procesar grandes volúmenes de datos de forma distribuida y escalable utilizando el modelo de programación MapReduce.
El componente principal de Apache Hadoop, HDFS (Hadoop Distributed File System), se ha convertido en el estándar mundial de servicios de almacenamiento distribuido. Algunos de los de los principales proveedores como, por ejemplo, Amazon o Google lo utilizan en sus servicios cloud.
Apache Hadoop se ha convertido en el estándar mundial de servicios de almacenamiento distribuido.
Hadoop ha sido diseñado para almacenar y procesar datos en paralelo empleando clusters o agrupaciones de servidores, lo que permite procesar grandes volúmenes de datos sin ver comprometido el tiempo de respuesta. Al funcionar mediante clusters, es posible escalar el sistema aumentando o disminuyendo el número de servidores empleados, lo cual supone una gran ventaja respecto a los sistemas de almacenamiento tradicionales.
Apache Spark
Al igual que Apache Hadoop, Apache Spark se trata de un framework open source de procesamiento distribuido y escalable basado en el modelo de programación MapReduce que permite procesar grandes volúmenes de datos empleando clusters.
Entonces, ¿qué diferencia hay entre Apache Spark y Apache Hadoop?
Apache Spark es una evolución de Apache Hadoop que trabaja en memoria y, además, aplica una serie de optimizaciones a las operaciones y transformaciones a realizar sobre los datos, por lo que puede llegar a procesar datos hasta 100 veces más rápido que su predecesor, lo que permite procesar datos en tiempo real mediante su módulo Spark
Streaming.
Apache Spark puede llegar a procesar datos hasta 100 veces más rápido que Apache Hadoop
Pero no siempre es posible trabajar en memoria. Cuando se han de procesar ficheros muy pesados o una gran cantidad de información que sobrepasa en tamaño a la memoria disponible, hay que trabajar en disco, lo que supone una pérdida de velocidad considerable. La buena noticia es que Spark permite combinar ambas estrategias y procesar parte en memoria y parte en disco, consiguiendo un equilibrio.
Además proporciona una API para Java, Scala, Python y R, los lenguajes de programación más empleados en el mundo Big Data.
ELK
ELK son las siglas de tres proyectos open source:
- Elasticsearch es un motor de búsqueda y analítica distribuido RESTful basado en documentos tipo JSON. Se trata de una base de datos NoSQL que permite indexar y analizar en tiempo real grandes volúmenes de datos. Los casos de uso más comunes de Elasticsearch son la búsqueda de texto completo, el autocompletado y la búsqueda instantánea, a lo que estamos más que acostumbrados con el buscador de Google.
- Logstash es una herramienta de ETL (Extract, Transform and Load) que permite extraer datos de una multitud de fuentes de forma simultánea, realizar transformaciones sobre los mismos y almacenar dichos datos en diversos sistemas de almacenamiento, como por ejemplo HDFS o Elasticsearch.
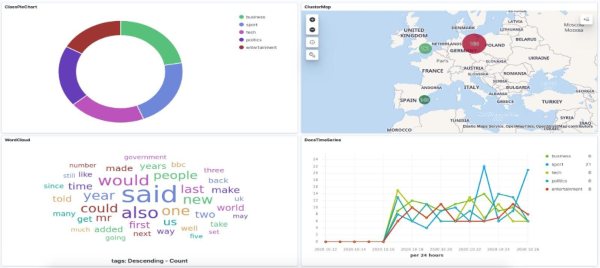
- Kibana permite visualizar y explorar en tiempo real grandes cantidades de datos almacenados en Elasticsearch a través de dashboards personalizados e interactivos, como el que se muestra en la siguiente imagen.
Python
Únicamente extrayendo y almacenando datos no se consigue un valor añadido para la organización. Es necesario dar un paso más y analizar los datos para extraer la información que contienen y poder tomar decisiones. Ahí es donde entra en juego Python.
Es un lenguaje avanzado de programación orientado a objetos que es
relativamente sencillo de emplear y que se ha convertido en el más utilizado en el campo de la analítica de datos y el aprendizaje automático o machine learning gracias a una gran comunidad de desarrolladores y científicos de datos que emplean este lenguaje de programación y han ido desarrollando muchas librerías y paquetes.
La única pega que tiene Python es que no es un lenguaje excesivamente rápido en su ejecución, por lo que se suele emplear para tareas de analítica o procesamiento de datos que no requieran de una gran velocidad de procesamiento.
Machine Learning
A pesar de que el machine learning o aprendizaje automático no es una disciplina científica nueva, ha irrumpido con gran fuerza en los últimos años debido principalmente a dos factores:
- El aumento exponencial en la capacidad de cálculo.
- El volumen de datos generados y almacenados.
El machine learning es un campo de la inteligencia artificial que consiste en una serie de algoritmos basados en cálculos estadísticos que son capaces de aprender en base a ejemplos o extraer patrones o relaciones de los datos. Por lo tanto, cuantos más datos haya disponibles, más ejemplos se podrán aportar a los algoritmos y mejor se podrán ajustar a la realidad.
La aplicación de algoritmos de machine learning supone el siguiente paso a la analítica de datos, ya que no sólo analizan los datos del pasado para extraer información y tomar decisiones, sino que son capaces de modelar comportamientos y, por ejemplo, hacer predicciones y anticipar la rotura de una máquina pudiendo realizar el mantenimiento pertinente antes de que sea tarde con el ahorro en costes que ello supone.
Las librerías más utilizadas en este campo son:
- Scikit-learn.
- Tensorflow.
- Pytorch.
Todas ellas están disponibles como paquetes de Python.

Conclusión: unas herramientas cada vez más necesarias
Vivimos en una era en la que se requiere y se genera una cantidad incalculable de datos.
Yo mismo me quise especializar en esta área cursando el Máster en IA & Big Data de EDEM, un programa práctico que abre un amplio abanico de oportunidades laborales y que me ayudó a obtener mi puesto de trabajo actual como ingeniero de inteligencia artificial en Cecotec.
Como he comentado en este post, simultáneamente a esta época de generación continua de datos, se han desarrollado herramientas robustas que son capaces de extraer, analizar, almacenar y visualizar dichos datos correctamente.
Las herramientas Big Data mencionadas en este artículo son un ejemplo de ello. Ambos factores forman la combinación perfecta para crear sistemas de decisión data-driven que permiten disminuir la incertidumbre y el riesgo.





![¿Dónde estudiar inteligencia artificial en España? - [GUÍA]](https://edem.eu/wp-content/uploads/2025/12/estudiar-inteligencia-artificial-300x300.jpg)






