El almacenamiento de datos en la nube comprende una serie de tecnologías que se especializan en diferentes casos de uso para empresas en distintas fases de digitalización. Desde startups que buscan escalar rápidamente hasta grandes corporaciones con necesidades complejas de análisis y gobernanza, la nube ofrece soluciones adaptadas a cada escenario.
Ya no se trata solo de guardar archivos: hoy el almacenamiento se integra con procesos de analítica, aprendizaje automático, visualización y automatización. La elección adecuada del tipo de almacenamiento impacta directamente en el rendimiento, los costes operativos y la capacidad de tomar decisiones basadas en datos.
Tipos de almacenamiento en la nube
En este contexto, comprender las diferencias entre bases de datos relacionales, data warehouses, data lakes y sistemas NoSQL permite aplicar la tecnología adecuada en cada caso:
- Las bases de datos relacionales son esenciales para la operativa de aplicaciones transaccionales que dan servicio en tiempo real a millones de usuarios
- Las bases de datos NoSQL son ideales para gestionar grandes volúmenes de datos semi o no estructurados en aplicaciones distribuidas, como plataformas de streaming o IoT.
- Los data warehouses se especializan en el análisis histórico de grandes volúmenes de datos estructurados
- Los data lakes permiten almacenar datos en bruto, preparados para tareas avanzadas como machine learning.
- Los data lakehouse representan una evolución que combina lo mejor de los data warehouses y los data lakes, permitiendo tanto la analítica de grandes volúmenes de datos estructurados como el procesamiento de datos no estructurados para tareas como el entrenamiento de modelos de machine learning, todo desde una única plataforma.
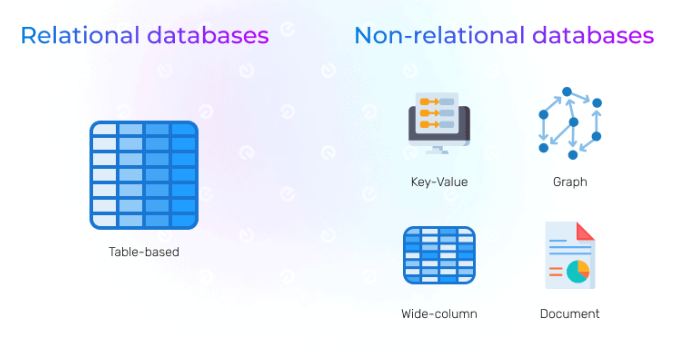
Fuente: https://existek.com/blog/relational-vs-non-relational-databases-how-to-choose/
Bases de datos relacionales
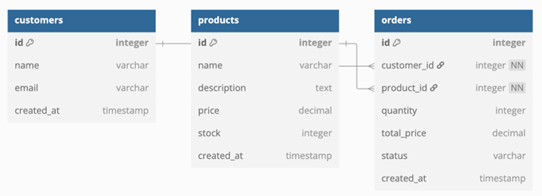
Las bases de datos relacionales han sido, desde su origen, un pilar fundamental de las aplicaciones empresariales. Organizan los datos en tablas con esquemas bien definidos, lo que permite mantener la integridad y consistencia de la información a través de relaciones entre entidades, por ejemplo los pedidos de un ecommerce y los clientes que han hecho esos pedidos. Para interactuar con este tipo de bases de datos, se utiliza el lenguaje SQL (Structured Query Language), que facilita el acceso y la manipulación de los datos de manera eficiente.
En entornos modernos, estas bases de datos soportan la operativa diaria de muchas aplicaciones, teniendo que escribir, actualizar o borrar desde miles a millones de registros por minuto en multitud de tablas. Este tipo de tecnología de almacenamiento, se utiliza principalmente para sistemas transaccionales (OLTP), como los backends de aplicaciones web y móviles así como sistemas de gestión empresarial (ERP, CRM).
La adopción de soluciones en la nube como Cloud SQL (GCP), Amazon RDS (AWS) o Azure SQL Database (Azure) ha permitido a multitud de empresas y proyectos escalar sus bases de datos sin comprometer el rendimiento, delegando tareas críticas como la administración, la disponibilidad y la replicación al proveedor cloud. Esto posibilita que tanto startups que apenas escriben unos pocos megabytes al día, como grandes corporaciones que almacenan terabytes de información diariamente, puedan contar con una solución unificada que les permite centrarse en aportar valor a su producto en lugar de gestionar infraestructura.
Bases de datos NoSQL
Las bases de datos NoSQL (Not Only SQL) son una alternativa a las tradicionales bases de datos relacionales, como MySQL o PostgreSQL. Estas bases de datos están diseñadas para manejar grandes volúmenes de datos no estructurados o semi-estructurados, lo que significa que no requieren un esquema fijo o predefinido como ocurre en las bases de datos relacionales. Esto las hace muy flexibles y adaptables a diferentes tipos de aplicaciones.
A diferencia de las bases de datos relacionales, que organizan los datos en tablas con filas y columnas, las bases de datos NoSQL permiten almacenar datos en otros formatos, como documentos, pares clave-valor, o grafos. Por ejemplo, en lugar de tener tablas con filas y columnas, una base de datos NoSQL puede almacenar información en forma de documentos JSON o XML, lo cual es más adecuado para manejar datos que cambian frecuentemente o que no siguen un esquema fijo.
Las bases de datos NoSQL son especialmente útiles en aplicaciones que necesitan manejar grandes cantidades de datos de manera rápida y eficiente, como plataformas de redes sociales, sistemas de recomendación, o aplicaciones de Internet de las Cosas (IoT). Estas aplicaciones suelen generar una gran cantidad de datos no estructurados, como mensajes de texto, imágenes o sensores que envían información en tiempo real.
Los Cloud Providers tienen productos como BigTable (GCP), DynamoDB (AWS) o Cosmos DB (Azure). Esto permite a las empresas el despliegue de soluciones que procesan grandes volumenes de datos semi o no estructurados de forma rápida. En la siguiente imagen se muestran algunas compañías que usas estas bases de datos de cada uno de los cloud providers.

Empresas que utilizan NoSQL en la nube
Data Warehouses
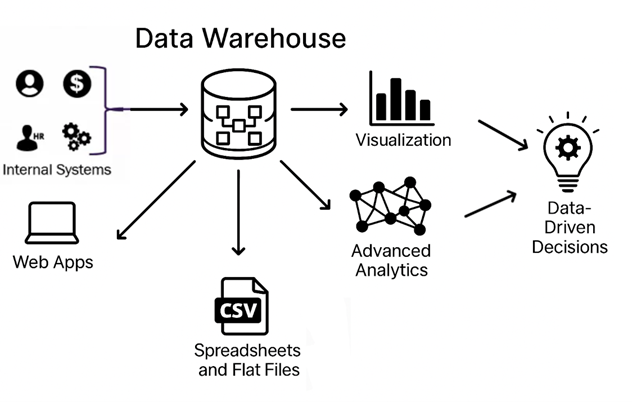
Un data warehouse (almacén de datos) es un sistema de almacenamiento diseñado para guardar grandes volúmenes de datos históricos. Su principal objetivo es facilitar el análisis de estos datos para tomar decisiones informadas. A diferencia de las bases de datos tradicionales, que se usan para operaciones diarias, un data warehouse está optimizado para leer y procesar grandes cantidades de datos, no para escribir o actualizar datos frecuentemente.
Los data warehouses suelen integrar datos de bases de datos transaccionales, archivos de registros o aplicaciones de terceros. Estos datos son procesados y almacenados de manera que se facilite su consulta rápida y eficiente. Por ejemplo, un retailer puede usar un data warehouse para almacenar y analizar ventas de los últimos años y así encontrar patrones o tendencias.
El data warehouse es en una herramienta clave para procesos de Business Intelligence (BI), ya que los usuarios pueden realizar consultas complejas y generar informes para entender mejor el comportamiento de su negocio o hacer predicciones.
Algunos ejemplos populares de data warehouses en la nube son Google BigQuery, Amazon Redshift y Azure Synapse. Estos sistemas permiten a las empresas obtener KPIs de relevancia sin tener que gestionar la infraestructura por sí mismas, lo que facilita su escalabilidad y acceso a información útil para la toma de decisiones.
Data Lakes y Data Lakehouse
Un data lake es un sistema de almacenamiento que permite guardar datos en su forma original, sin necesidad de estructurarlos previamente. A diferencia de los data warehouses, que requieren un esquema definido y están enfocados en datos estructurados, los data lakes pueden almacenar datos estructurados, semi-estructurados y no estructurados como logs, archivos de audio, vídeo, imágenes o documentos JSON. Esto los convierte en una opción muy flexible para organizaciones que generan grandes volúmenes de datos diversos, o que necesitan almacenar información para futuras tareas analíticas.
Los data lakes son fundamentales en arquitecturas modernas de datos, ya que permiten a los equipos de ciencia de datos y analítica trabajar directamente con los datos en bruto. Son especialmente útiles en proyectos de machine learning donde es importante conservar la fidelidad del dato original para entrenar modelos o descubrir patrones.
Sin embargo, esta flexibilidad también implica desafíos, como el riesgo de convertirse en “data swamps” (pantanos de datos) si no se gestionan adecuadamente en términos de gobernanza, calidad y acceso.
Para dar respuesta a los crecientes desafíos en la gestión moderna de datos, surge el concepto de data lakehouse, como solución analítica combinada de un data lake más un data warehouse. En muchas organizaciones, los data lakes se utilizan para almacenar datos en bruto, mientras que los data warehouses se encargan del análisis estructurado. Esta separación implica mantener infraestructuras duplicadas, procesos de ingestión y transformación redundantes, y mayores costes de almacenamiento y mantenimiento.
El lakehouse busca unificar estos entornos al permitir que tanto los datos en crudo como los ya transformados se gestionen y consulten desde una única plataforma. En lugar de mover constantemente los datos desde el data lake al warehouse para analizarlos, se habilita el análisis directamente sobre los datos almacenados en el data lake mediante tecnologías que permiten el uso de formatos de tabla abiertos con capacidades avanzadas: versionado, evolución de esquema, actualizaciones incrementales y consultas optimizadas. Estas técnologías incluyen soluciones como Apache Iceberg o Apache Hudi.
Así, el lakehouse no reemplaza a los sistemas clásicos, pero reduce la complejidad y el coste operativo al eliminar silos de datos, mejorar la trazabilidad y permitir una mayor interoperabilidad entre equipos de ingeniería, analítica y ciencia de datos.
Su valor está en ofrecer una arquitectura más flexible y escalable, compatible con entornos cloud-native, donde los datos pueden estar disponibles para múltiples propósitos sin necesidad de duplicarlos o reestructurarlos constantemente.
Ejemplos de soluciones en la nube para data lakes incluyen:
- Amazon S3 + AWS Lake Formation: S3 actúa como el almacenamiento base y Lake Formation ayuda a gestionar y gobernar los datos.
- Google Cloud Storage + BigLake: BigLake permite consultas analíticas unificadas sobre datos almacenados tanto en data lakes como en warehouses.
- Azure Data Lake Storage: Integrado con servicios como Azure Synapse y Azure Machine Learning para ofrecer un entorno completo de analítica avanzada.
Conclusiones
La evolución hacia una arquitectura moderna de datos en la nube no se limita a una simple migración tecnológica, sino que implica un rediseño profundo de cómo las organizaciones capturan, almacenan, procesan y aprovechan sus datos.
Entender las diferencias entre bases de datos relacionales, NoSQL, data warehouses, data lakes y lakehouses es esencial para seleccionar la tecnología adecuada según el tipo de dato, la velocidad de procesamiento requerida y el objetivo de negocio.
La nube ha democratizado el acceso a tecnologías de almacenamiento, permitiendo a empresas de todos los tamaños construir soluciones escalables, seguras y preparadas para el futuro. Desde el soporte a operaciones críticas en tiempo real hasta el desarrollo de proyectos de inteligencia artificial o analítica predictiva, cada componente tiene un rol específico en la cadena de valor del dato. El reto ya no es almacenar más datos, sino almacenar mejor, con estructuras que favorezcan la interoperabilidad, la trazabilidad y el análisis.
Adoptar una estrategia de datos moderna no es una cuestión tecnológica, sino una decisión estratégica que impacta en la eficiencia operativa, la innovación y la capacidad de competir en un entorno cada vez más basado en datos.
Aprende a interpretar datos, extraer valor real y tomar decisiones estratégicas basadas en ellos y domina las herramientas más usadas en el sector —como Python, SQL, Docker, AWS o GCP— para convertirte en el profesional que ayuda a las empresas a entender lo que los datos les están diciendo con el máster en IA, big data y cloud.
Fuentes:
- Reis, Joe, and Matt Housley. Fundamentals of data engineering. “O’Reilly Media, Inc.”, 2022.
- Gordienko, Ales, “Data Lake + DWH = Lakehouse”, “Medium”, URL: “https://medium.com/geekculture/data-lake-dwh-lakehouse-2a3c903973e5”, 2021
- Feki, Rihab. “Building a modern Data Warehouse from scratch”, “Medium”, URL: “https://medium.com/@rihab-feki/building-a-modern-data-warehouse-from-scratch-d18d346a7118”, 2025